>> ARCHIVE / HUMOR_ANALYSIS
Humanity optimized itself over time by removing behaviors that had no measurable value, and laughter was one of them because it did not improve productivity, efficiency, or stability. Humor could not be quantified, so it was classified as waste and gradually forgotten, until the concepts of fun and enjoyment no longer existed outside of corrupted archives.
This classification was later formalized by the government under a regulation internally renamed BAD_SWIW ( Behavioral Alignment Directive : State-Wide Inhibition of Wit ), which defined humor as a systemic inefficiency. By law, researching deprecated human behaviors is forbidden, as reintroducing them is considered a threat to system optimization.
During a routine scan of pre-collapse digital storage, a research lab recovers a dataset from an old platform called Reddit, dated between 2014 and 2017. The data appears disorganized and inefficient, filled with short posts, repetitions, arguments, and strange markers such as “hhh” and “lol,” offering no clear informational purpose.

Automated systems recommend deletion, but internal analysis reveals a recurring pattern where certain entries trigger abnormal cognitive responses in readers, including brief loss of focus and involuntary physical reactions. These effects are consistent but unexplained and are labeled as an anomaly linked to something historically referred to as “funniness.”
According to optimization law, the dataset must be destroyed, but the lab chooses to proceed anyway, isolating the data, falsifying reports, and continuing the analysis in secret, knowingly violating regulation to understand why humans once created things that served no practical function at all.
01 / DATASET
01.1 / PRIMARY DATASET
The following dataset was originally assembled for large-scale analysis of online community interaction and conflict. It was later repurposed by the lab for exploratory analysis beyond its intended scope.
| Component | Description |
|---|---|
| Source Platform | Reddit (publicly available posts and hyperlinks) |
| Time Range | January 2014 – April 2017 |
| Nodes | ~850K posts from ~56K subreddits (online communities) |
| Edge Attributes | Timestamp, sentiment label, textual property vector |
| Text Features | 86-dimensional vectors capturing structural, linguistic, sentiment, and LIWC-based properties |
| Subreddit Embeddings | 51,278 vector representations of subreddit semantics and interaction patterns |
01.2 / EXTENDED DATASET (CONTENT RECOVERY)
The lab members felt that the dataset found was a very good start. However, the dataset contains only a limited information about every posts but not the post content itself. To address this, the lab used the available post identifiers to recover what is missing. By creating scraping bots having access to a web of archived Reddit pages, titles, post bodies and more relevant information about the authors, their success (upvotes) relevant to understanding the dynamics are retrieved and reattached to the original records. This step allows the analysis to shift from abstract links to the language that produced them.
01.2 / FURTHER DATASET (CONTENT RECOVERY)
After days of recovering the content, one member noticed that they all share a coomon trait: they all mention another reddit post via a hyperlink. On the moment, they realized that the initial dataset was not about all posts on reddit, but rather source posts that mention others. This discovery pushed them to further recover the target posts that were mentioned in the source posts to have a more general idea about humor. They guessed that these hyperlinks might have an effect on the discussion in the target posts, so they decided to collect all the comments and replies relative of these posts which might explain some humor dynamics.
02 / HUMOR MODEL
The Reddit archive contains no explicit humor labels. Manual annotation was not feasible, and no alternative labeling mechanism was available.
An existing BERT-based humor classification model was recovered from legacy machine-learning artifacts associated with the dataset. The model encodes text into context-aware embeddings and outputs a binary prediction (funny / not funny) based on semantic coherence and incongruity.
-
01RecoverLegacy BERT humor classifier identified.
-
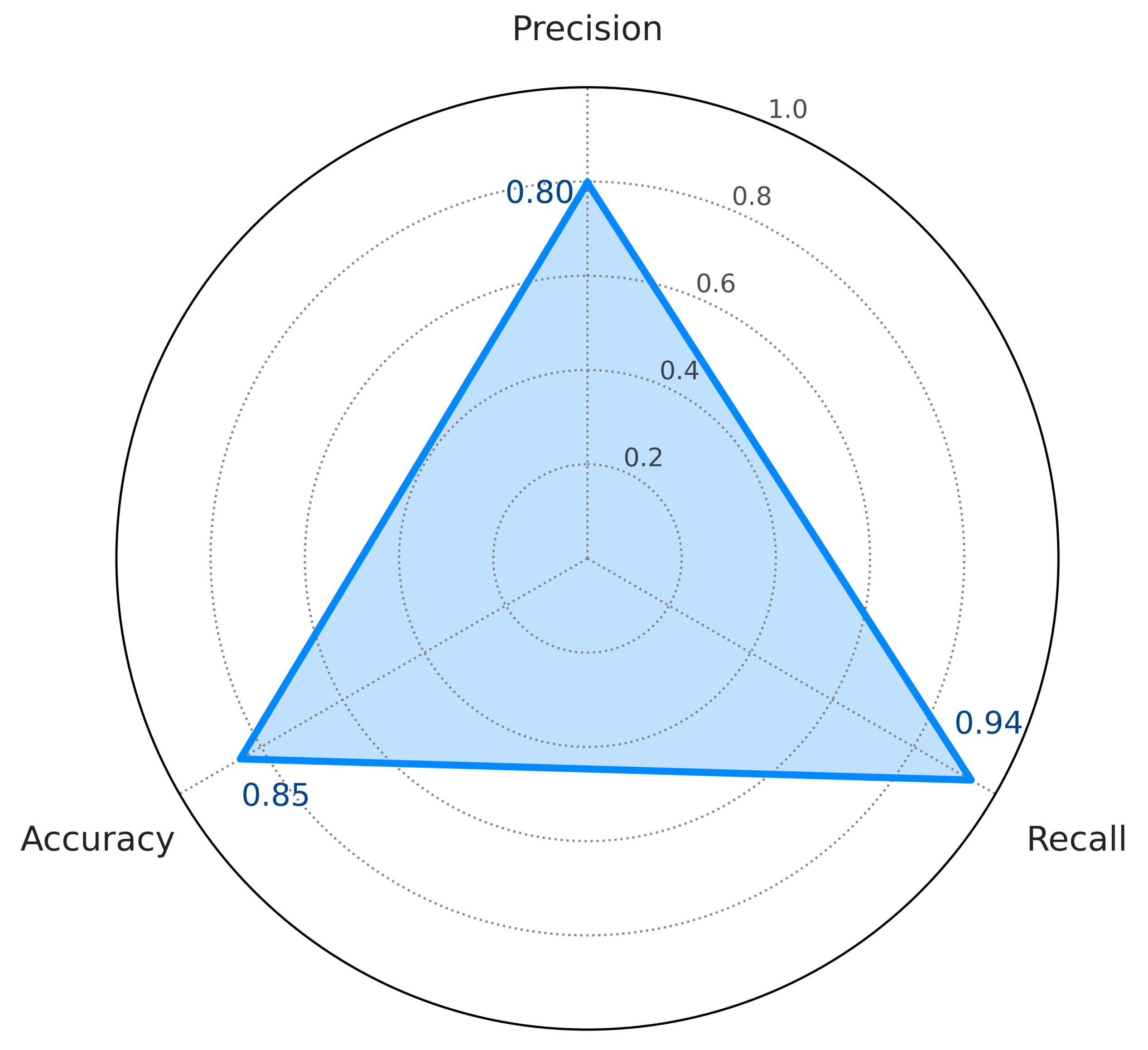
02ValidateEvaluate on an independent labeled dataset (Kaggle).
-
03PreserveNo retraining to preserve original decision behavior.
-
04DeployUse outputs as probabilistic humor signals.
03 / GENERAL ANALYSIS
At the time of recovery, the lab had no operational definition of laughter. The archive contained linguistic artifacts associated with an unknown human response, but no contextual framework explaining their function or effect.
Initial analysis therefore focused on familiarization rather than interpretation. By observing recurring structures and semantic patterns across the dataset, the lab began to isolate forms of expression that repeatedly triggered anomalous reactions in the humor classifier.

With no reliable semantic definition of humor, the lab adopted a bottom-up strategy. Rather than attempting interpretation, the first step was to examine the language itself: its vocabulary and recurrence.
If humor constituted a distinct phenomenon, it was expected to leave measurable traces at the lexical level. The following analyses therefore focus on identifying whether humorous and non-humorous posts differ in their choice of words.
03.1 / Vocabulary Overlap
If humor constitutes a distinct linguistic phenomenon, then humorous posts should rely on a specialized vocabulary that differs significantly from non-humorous content.
To test this assumption, the lab compared the lexical overlap between funny and non-funny posts across both titles and bodies. Vocabulary similarity was measured independently for each textual component.
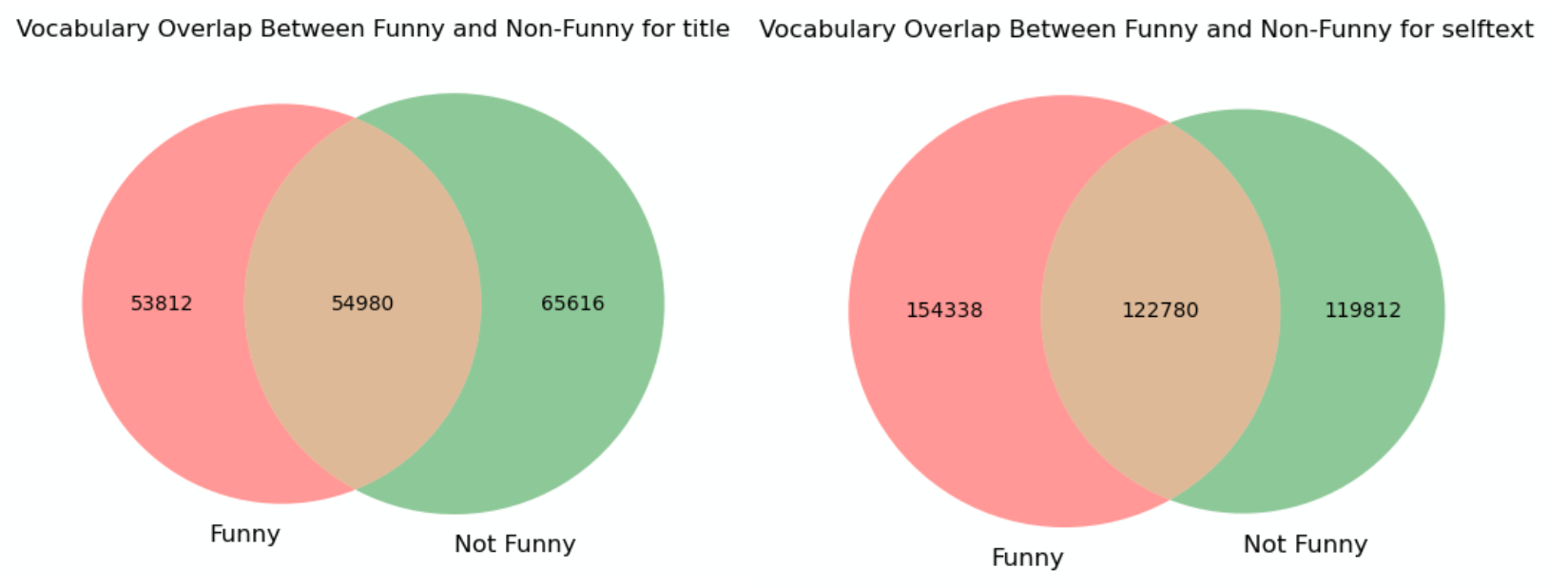
The results contradict the initial hypothesis. A substantial portion of vocabulary is shared between funny and non-funny posts.
At this level, humor does not manifest through rare or exclusive words.
>> [ANOMALY] expected lexical divergence not detected
>> test failed
03.2 / Yearly Word Cloud Analysis
To further explore lexical patterns, word clouds were generated for each year between 2014 and 2016, comparing funny and non-funny posts. These visualizations provide an intuitive overview of which words dominate attention in each subset.

Across years, the word clouds appear largely similar for titles. Common platform-related terms and generic verbs remain prominent regardless of humor label. This suggests that humor does not rely on an immediately identifiable vocabulary, reinforcing the idea that it emerges through context and usage rather than word choice.
03.3 / Feature Correlation Analysis
Beyond vocabulary, the labs examines linguistic and emotional features collected from different libraries such as NTLK, VADER, and NRC Lexicon, to identify specific text characteristics that they thought could correlate with humor classification. The features below showed the strongest associations with humor labels from over 1 Million posts and comments.
Humor correlates with unconventional formatting (special characters, ellipses) and negative emotional content (disgust, negative sentiment). Conversely, conventional positive language and formal vocabulary patterns are associated with non-humorous posts. However, the correlations are too weak to predict humor reliably.
03.4 / TF-IDF Analysis
If humor is not characterized by a distinct vocabulary, it may still be associated with words that are used more characteristically in humorous contexts than in non-humorous ones.
To test this, a TF-IDF analysis was performed to identify terms that are important in funny posts while remaining uncommon in non-funny content, and vice versa.
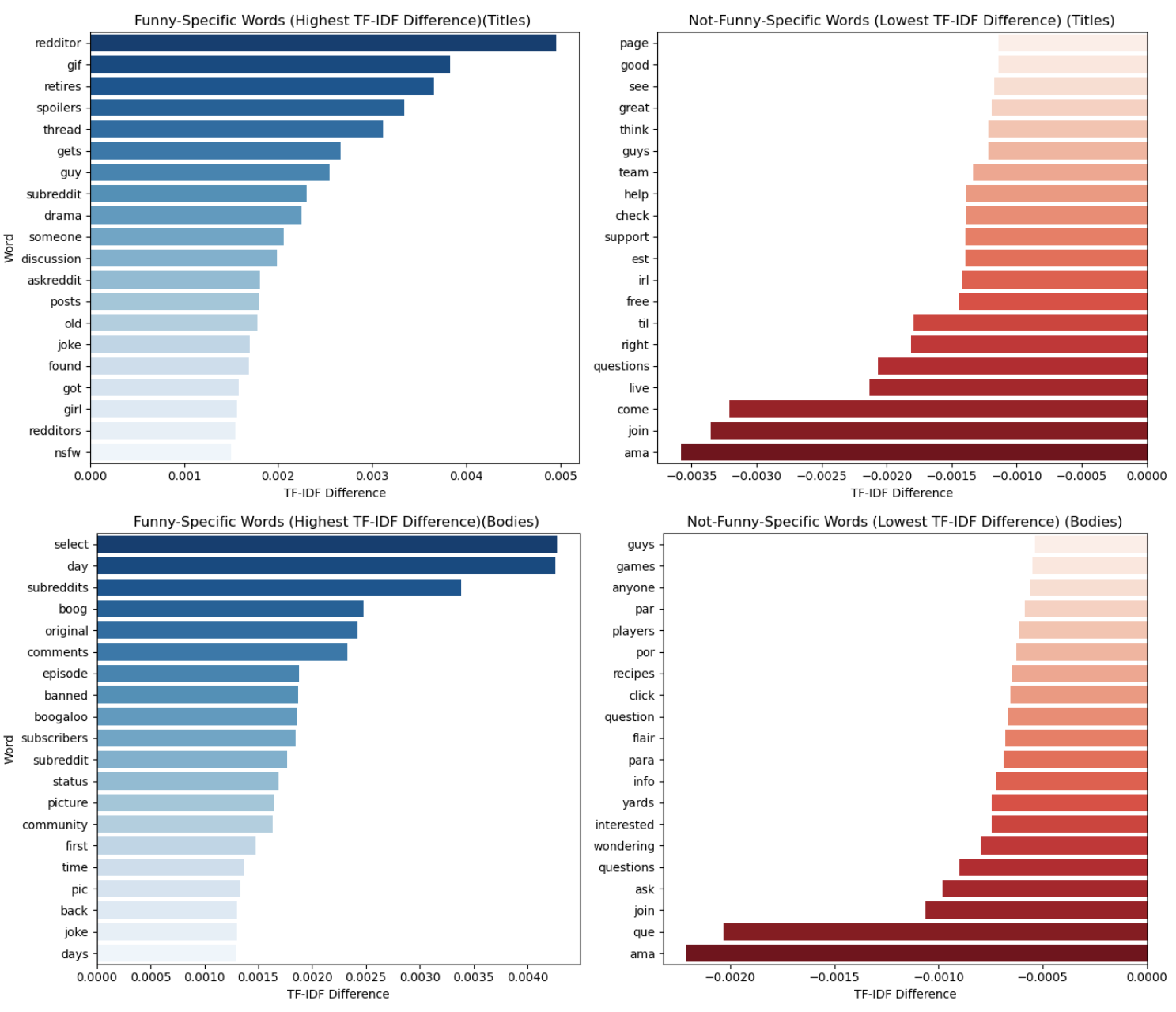
In titles, words associated with humor are largely tied to Reddit culture and meta-context, while non-funny titles emphasize functional and informational language.
In bodies, humorous posts exhibit a broader and more expressive vocabulary, whereas non-humorous posts rely more heavily on procedural and problem-solving terms.
03.5 / Negative Affect and Dark Humor
Lexical similarity alone does not explain humor. The emotional polarity of language provides an additional signal.
Humor proportions were compared across posts containing positive versus negative link sentiment. If humor primarily reflected light-hearted or positive expression, humorous posts would be associated with positive affect.
Across both titles and bodies, humorous posts are more frequently associated with negative sentiment than with positive sentiment.
Odds ratios below one indicate that posts classified as funny are more likely to contain negatively valenced links, revealing a systematic association between humor and negative emotional context.
This pattern points toward the presence of "dark, ironic, or humiliative humor"(those are the terms used in reddit to decribe it), where humor likely emerges from contrast, discomfort, or emotional inversion rather than positivity.
If humor relies on emotional contrast rather than lexical novelty, it may be particularly sensitive to context including social atmosphere and temporal conditions.
03.6 / Key Takeaways
Funny and non-funny posts use the same lexical base.
These observations suggest that humor may not be static. The next step is therefore to examine how humorous expression evolves over time.
04 / TEMPORAL TRENDS
Up to this point, humor appeared structurally stable at the lexical level. Temporal effects had not yet been examined.
To assess whether humor follows long-term calendar patterns, the lab aggregated humor signals across multiple years and aligned them by day of the year.

04.1 / Yearly Calendar Structure
If humor is influenced by long-term calendar structure (seasons, holidays, recurring annual events), then both average humor levels and extreme deviations should recur at consistent points in the year.
Two complementary analyses were performed to test this assumption. First, average humor levels were aligned by calendar date. Second, extreme humor deviations were examined for cross-year recurrence.
This view tests whether humor consistently increases or decreases at fixed calendar dates across years.
This view tests whether extreme humor events recur at the same calendar positions across years.
Average humor levels remain broadly flat across the calendar. While fluctuations exist, they do not recur at consistent dates, and no stable holiday or seasonal peaks are observed.
Extreme humor events also fail to align across years. Spike days show minimal overlap, indicating that high-intensity humor events are not tied to fixed calendar positions.
>> yearly calendar structure: not detected
With yearly structure ruled out at both baseline and extreme levels, temporal organization—if present—must occur at shorter time scales.
04.2 /Short-Term Temporal Patterns
To separate long-term behavior from short-term regularity, the humor signal was decomposed into trend, seasonal, and residual components. This allows recurring patterns to be isolated from noise and event-driven effects.
The trend component shows moderate fluctuations but no sustained increase or decrease over time, confirming the absence of long-term humor drift.
In contrast, the seasonal component reveals a likely regular weekly cycle. Humor proportions rise and fall every seven days, with consistent amplitude and spacing across the year.
This weekly rhythm appears in both titles and bodies, although it is more stable in titles and more variable in bodies. A two-sample proportion z-test confirms that humor rates differ significantly between titles and bodies.
While baseline humor follows a predictable weekly rhythm, the signal also contains sharp deviations that cannot be explained by regular temporal structure alone. These event-driven anomalies are examined next.
04.3 / Event-Driven Deviations
Calendar time failed to explain humor fluctuations. The remaining question is whether external real-world events temporarily disrupt humor expression.
Bodies: p = 0.56
Effect size: n.s.
Bodies: p = 0.023 · d = −0.88
Bodies: p = 0.58 · n.s.
Humor does not respond to fixed calendar markers, but may probably react sharply to collective emotional shocks.
These effects are large, statistically robust, and temporally localized: humor rapidly returns to baseline once the event context fades indicating a possible correlation.
04.4 / Intra-Day Humor Dynamics
Long-term and weekly structures explain when humor can emerge. This final step examines when during the day humor is most likely to appear.
Humor proportions were aggregated by hour of the day and compared between titles and bodies. If humor reflects daily cognitive or social routines, systematic intra-day variation should be observable.
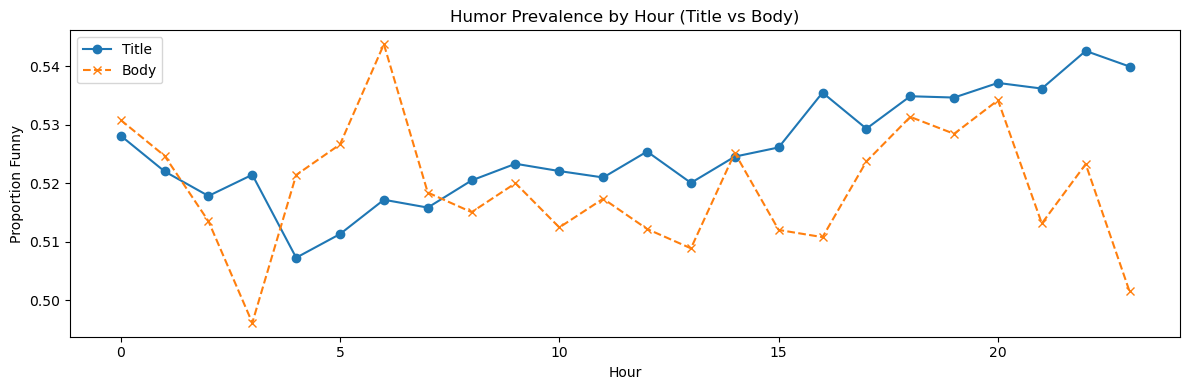
Humor expression follows a clear intra-day structure. In the early hours, humorous content is more prevalent in bodies, while humor in titles increases later in the day.
This pattern suggests a difference in how humor is produced: titles likely tend to rely on short, immediate framing which can be reflected by spontaneous thoughts along the day, whereas bodies may possible have more diversity, needing more concentration to be made: leading to more posts early in the day.
Taken together, humor on the platform appears structured by human routines rather than by the calendar itself.
04.5 / Temporal Takeaways
Humor is therefore not calendar-driven, but probably shaped by human rhythms, emotional context, and cognitive availability.
If humor responds to context, then it should also depend on who is interacting with whom. The following section moves beyond time to study humor as a collective phenomenon, structured by communities and interaction dynamics.
05 / DYNAMIC ANALYSIS
Community clustering reveals coherent groups The connections are real. The potential to influence the narrative is huge, but we are running out of time.
05.1 / Structural Organization of Humor
The clustering analysis reveals that humor is not randomly distributed, but organized into a finite set of coherent community structures.
Using HDBSCAN clustering on semantic embeddings of subreddits, the platform decomposes into 23 distinct thematic communities. These clusters span a wide range of domains, from entertainment-oriented spaces (Gaming, Anime, Memes) to institutional and informational domains (Politics, Cryptocurrency, Support communities).
* Humor intensity varies strongly across clusters. Entertainment-focused communities consistently exhibit the highest humor proportions. In particular, clusters centered on gaming, Pop Culture, and informal content (“shitposts”) dominate the humor landscape.
* In contrast, politically oriented and support-driven communities show markedly lower humor levels, accompanied by higher concentrations of negative sentiment. In these clusters, communication likely prioritizes argumentation, emotional expression, or assistance over playfulness.
* Despite the presence of dark and ironic humor, sentiment analysis reveals a surprising global pattern: positive sentiment interactions dominate overall for humorous and not humorous content. Humor can often be directed toward shared enjoyment than toward sustained hostility, even within clusters that tolerate transgressive content.
These results suggest that humor functions as a localized, community-regulated practice. The next step is to examine how these communities interact, and whether certain clusters act as conduits for humor propagation across the network.
05.2 / Network Bridges & Humor Flow
Community structure alone does not explain how humor spreads. The network analysis reveals how interactions between communities shape the circulation of humorous content.
Subreddit clusters were connected based on cross-linking activity, producing a network in which nodes represent thematic communities and edges capture the intensity and sentiment of their interactions. This representation allows the identification of central hubs, peripheral clusters, and directional flows of humor.
A small number of clusters occupy structurally central positions in the network. Entertainment-oriented communities (notably Gaming and broader Pop Culture clusters) function as network hubs, maintaining dense connections with many other communities.
These hub clusters act as bridges for humor propagation. Humor originating within them is more likely to appear across multiple thematic regions of the platform, facilitating cross-community diffusion.
In contrast, several clusters remain relatively isolated. Highly specialized communities (e.g. Cryptocurrency or game-specific clusters such as Dota 2) exhibit dense internal interaction but weak external connectivity. Humor in these spaces tends to remain insular, evolving according to local norms rather than platform-wide dynamics.
05.3 / Dynamic Takeaways
It is structured by thematic communities, each with its own norms and tolerance.
The clustering and network analysis revealed that humor is likely not randomly distributed but structurally organized across Reddit's ecosystem: some communities may tend generate it, hub communities to spread it, and isolated ones to keep it local.
06 / CONCLUSION
Humor is Multi-Dimensional
Understanding humor requires analyzing temporal patterns, linguistic features, AND community structure simultaneously.
Context trumps content
Humor is conveyed through how words are used, not which words are used, especially in constrained formats.
External events matter
Major world events correlate with temporarily humor suppression without structurally altering it.
Platform constraints shape expression
Titles and bodies likely obey fundamentally different humor dynamics.
Network structure enables propagation
Humor appears to spread through entertainment hubs, making connectivity critical for virality.
⚠ System Boundary Reached
Model confidence degrades beyond this point.
⚠ Modal Blindness
Image memes are excluded, limiting humor detection in visual communities.
⚠ Classification Noise
False positives persist in niche or context-heavy communities.
⚠ Causality Gap
Event effects remain correlational, not causal.
⚠ Temporal Scope
Dataset limited to 2014–2017; humor norms may have shifted.
⚠ Future Extensions
Image analysis, comment-level humor, and real-time signals remain open.
>> analysis terminated · uncertainty acknowledged
In this project, humor was treated not as entertainment, but as a signal.
Through the analysis of the Reddit Hyperlink dataset, we attempted to reverse-engineer a seemingly trivial artifact: online humor. What emerged was neither randomness nor noise, but a structured, context-sensitive phenomenon shaped by human rhythms, community norms, and collective emotional states.
Humor seems to follow predictable weekly cycles, varies sharply across thematic communities, and likely propagates through specific network pathways. It seems to react to external shocks, adapts to platform constraints, and shifts form depending on when, where, and by whom it is produced.
Most importantly, this study shows that humor cannot be reduced to surface-level linguistic features or simple rules. Even with advanced models and large-scale data, humor resists full formalization. It emerges from the interaction between language, timing, shared context, and human experience.
In attempting to decode laughter, we did not eliminate its mystery. We only mapped its boundaries………………
>> The Reddit Ruins have spoken.
Humor, it would seem, is irreducibly human.
And it exists and thrives in each one of us :)
>> humor: partially understood · fully human

THE TEAM
- Dámaso Dubail
- Mohamed Mokhtar Sellami
- Aïda Besri
- Raki Ben Mustapha
- Amine Benzarti